
Activation-aware Weight Quantization (AWQ) for LLM Compression and Acceleration

Introduction
Large Language Models (LLMs) have made a big mark in AI, helping with various language tasks. But getting these models to run directly on our hardware is a challenge. Why? Well, the main issue is their sheer size. GPT-3, for instance, boasts 175 billion parameters. That’s a lot of data for even the most powerful Graphics Cards to handle.
Running LLMs directly on devices has some clear perks, though. It cuts down on the wait times we experience when data has to travel to and from cloud services. Plus, it keeps personal data safer since it doesn’t have to leave the device at all, reducing the risk of it falling into the wrong hands.
Quantization comes into the picture as a clever solution to shrink these models down to a size that is more easily manageable for smaller devices. The idea is to reduce the number of bits used to represent data in the model, thus lightening its load. But the usual methods have their issues. Techniques like quantization-aware training are quite resource-intensive, and post-training quantization often ends up hurting the model’s performance, especially when using fewer bits.
That’s where Activation-aware Weight Quantization (AWQ) comes in. It takes a different approach. Instead of focusing on all the weights equally, AWQ picks out a tiny fraction of the weights that matter the most. AWQ manages to keep the model’s performance intact while still making it more device-friendly. This makes running LLMs on our devices a lot more feasible.
What exactly is Quantization?
Quantization, in the simplest terms, is the process of reducing the precision of the numbers used in a model. Picture this: you’re tasked with fitting a vast library onto a single bookshelf. Instead of cramming every last pamphlet in, you’d prioritize the crucial volumes. When it comes to quantizing a machine learning model, it’s about asking whether we really need every single bit of precision, or if we can get away with less without noticing much difference.
Most models use 16 or 32 bits for every single number, but with quantization, we start to round those numbers down to use, say, just 8 bits. So, we’re essentially deciding how many decimals to snip off, to reach our desired balance between the model’s memory use and its performance. This technique translates to less memory usage and much faster computations, which is precisely what you want whether you’re running these models on a smaller server or your smartphone. Quantization therefore makes Machine Learning models more accessible and practical for everyone, reducing cloud dependence and keeping your hardware budget in check.
What is Activation-aware Weight Quantization?
Activation-aware Weight Quantization (AWQ) is a clever approach to make large language models more efficient by focusing on what truly matters within the model’s structure. Traditional quantization techniques reduce the precision of all the model’s numbers evenly, but AWQ flips this idea on its head by being selective about which weights are important. Instead of treating every component of the model equally, AWQ pinpoints the weights that are crucial for maintaining the model’s performance. By doing so, it manages to significantly cut down on quantization errors. This approach allows AWQ to preserve the essential features of the model using only about 1% of the weights in floating-point precision, without the need for complex re-training processes.
How AWQ Works
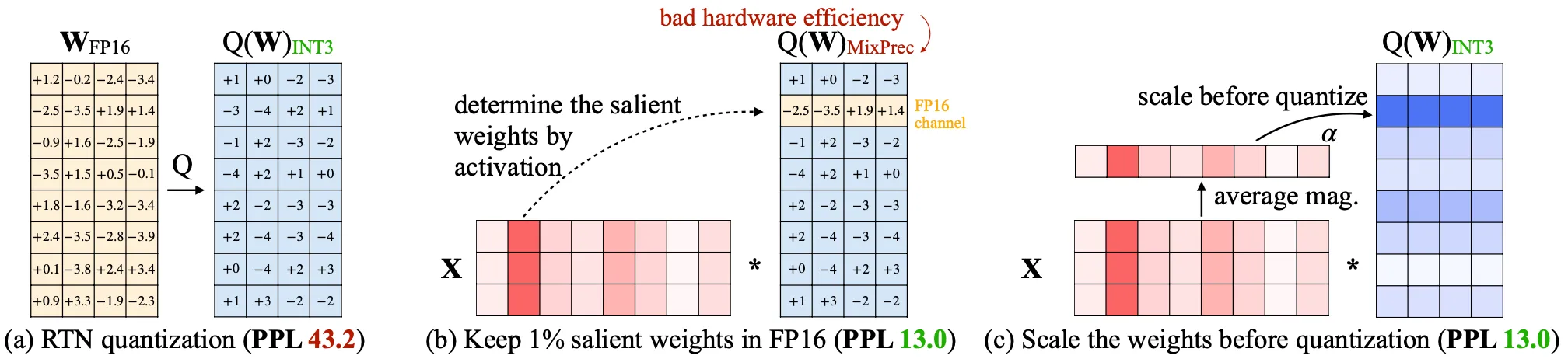
At the heart of AWQ is the notion that not all weights in a large language model are created equal. Through careful observation, it becomes clear that a small fraction of these weights, known as the “salient weights,” have an outsized impact on the model’s performance. Instead of uniformly applying quantization across the board, AWQ pinpoints this crucial 1% and treats them with special importance. By doing so, the solution bridges the gap in performance that usually presents itself when weights are indiscriminately lowered in bit precision.
Identification of Salient Weights
Instead of simply lowering the bit precision across the entire model indiscriminately, AWQ selectively focuses on the weights that are most significant for maintaining the model’s performance. This approach is all about activation-aware scaling, which means focusing on the activation distribution—not just weight distribution—to discern which weights matter most.
The process starts by analyzing the quantization error linked to weight-only quantization. AWQ reduces the error from quantization by applying “per-channel scaling” to those crucial weights identified through the lens of activation distribution—the salient weights. This involves multiplying these important weights by a factor greater than one, thereby preserving their impact on the model’s output. Using this insight into using activation statistics, Empirical studies show that slight increases in these pivotal weights lead to a substantial reduction in overall quantization error, without complicating hardware efficiency.
Scaling Salient Channels
Once AWQ identifies the salient weights, the next step is applying an activation-aware scaling method to them. This approach minimizes the quantization error in a manner amicable with hardware requirements, all without diving into the mixed-precision complexities.
Each of these critical weight channels gets multiplied by a scaling factor greater than one. It ensures the essential weights remain robust against the rounding process typical in quantization. The inputs that interact with these weights also get inversely scaled to maintain operational integrity. Even though one might expect that amplifying individual weights could throw off the entire group’s balance by altering the maximum value, experiments show otherwise. The max value remains steady, thereby preserving the quantization ruler for other weights in the cluster.
In practical terms, this scaling can lead to substantial benefits. Empirically, it has been shown that scaling the 1% salient channels significantly enhances model performance. Also, when scaling the channels by even modest amounts, notable improvements in model performance were observed, showcasing the applicability of this technique in bolstering model accuracy post-quantization.
Performance Metrics
When evaluating quantization techniques, two major performance metrics come into play: perplexity (PPL) and memory usage (MEM). These metrics help us understand how well a model not only holds its ground in terms of computational efficiency but also in maintaining its interpretative prowess.
Perplexity is a metric traditionally used in the realm of language models to gauge how well a model predicts a set of words. It’s essentially about uncertainty. Lower perplexity values indicate the model can predict the next word in a sequence with higher confidence. For AWQ, maintaining low perplexity despite fewer bits is a testament to its ability to retain model accuracy.
On the other hand, memory usage calculates how much system space a model occupies when running on a device. The goal of AWQ is, that the memory footprint can be significantly reduced while still performing tasks efficiently, which generally means having a low perplexity.
AWQ Performance
When it comes to assessing AWQ’s performance, especially compared to other quantization techniques, it’s crucial to look at both the model’s perplexity and memory usage. A recent deep dive into Llama models offers some insights into how AWQ stacks up against other methods. Let’s take a closer look at some of the data.
Here’s an excerpt of quantization schema results from the Llama-2 series, measuring PPL and MEM:
| Method | nBits | Llama-2-7B | Llama-2-13B | Llama-2-70B | |||
|---|---|---|---|---|---|---|---|
| PPL (↓) | MEM (↓) | PPL (↓) | MEM (↓) | PPL (↓) | MEM (↓) | ||
| FP | 16 | 5.18 | 13.5 | 4.63 | 25.6 | OOM | OOM |
| BNB | 8 | 5.22 | 7.9 | 4.67 | 14.4 | 3.17 | 68.15 |
| GPTQ_g128 | 8 | 5.19 | 7.8 | 4.63 | 14.8 | 3.12 | 74.87 |
| AWQ_g64 | 4 | 5.28 | 4.6 | 4.7 | 8.5 | 3.2 | 37.08 |
From the data, it’s quite evident that while full-precision (FP) models offer the lowest perplexity, they are often impractical due to their exorbitant memory consumption, particularly with larger models like Llama-2-70B where they run out of memory (OOM).
The 8-bit quantized methods, such as BNB and GPTQ, deliver a fairly solid balance, lowering memory demands significantly while only slightly compromising on perplexity. Yet, when we transition to the largest 70B parameter model combined with 4-bit quantization methods, this is where AWQ truly shines.
AWQ_g64 registers a perceptible dip in perplexity, closely trailing its 8-bit counterparts, yet manages to excel in memory efficiency. For instance, with Llama-2-70B, AWQ cuts down memory usage to 37.08 from the 68.15 achieved by its closest 8-bit competitor. This trade-off between reduced memory and sustained performance highlights AWQ’s serious potential for on-device applications where resource efficiency is essential.
Conclusion
Activation-aware Weight Quantization has emerged as a promising solution in the endeavor to compress LLMs for efficient deployment on limited hardware. This technique stems from the understanding that not all weights in LLMs carry the same significance. By strategically identifying and scaling the critical weights, AWQ smartly reduces quantization losses without burdening the computational resources.
By steering clear of overfitting with the calibration dataset, AWQ manages to preserve the versatile capabilities of LLMs across a multitude of domains. What makes it even more attractive is its applicability to both instruction-tuned language models and multi-modal systems, marking an improvement over older quantization methods.